Java中的String在JVM运行时都是Unicode编码的
字符集
在计算机的世界里,我们需要表示太多太多的字符,为了计算机能够正确的显示这些字符,我们将这些字符编码,使得字符和一系列的代号一一对应。当我们的系统按照一种编码方式去读取一个文件的时候,会自动的将里面的编码转换成相应的字符显示在屏幕上。(我们这里并不讨论如何将字符在显示器上通过点阵的方式显示的这个过程) 中文由于其字符数多,其编码方式自然比西方的字符复杂。所以在编写代码,软件使用的过程中,我们经常碰到中文乱码的相关问题。
g.cn的首页是UTF-8的编码(浏览器会首先根据接受到的html自动检测其编码),这个时候如果我们强行以GB2312的编码来解析页面的话就会显示如上的乱码。 这是为什么呢??? 首先我们请求一个网址,服务器返回的内容是以指定字符集编码的字节传到浏览器端的,浏览器再按照一定的编码方式去解析这些字节。但是如果传来的正确的字节的编码方式和你解析字节的编码方式不一致,那么就会乱码。
下面我们先介绍几种日常使用中经常碰到的编码。
在我们的日常使用中,我们会碰到iso 8859-1,gb2312,gbk,gb18030,big5,unicode等字符集或者说字符编码,这些都是同一个层次的概念,有些同学可能会问,那UTF-8,UTF-16呢?其实unicode是比较特殊的,虽然通过unicode编码,每一个字符对应一个唯一编码,但是其在计算机上的实现方式却可以有好几种,Unicode的实现方式称为Unicode转换格式(Unicode Translation Format,简称为UTF),所以说UTF-8或者UTF-16只是Unicode编码的一种实现方式。下面我们单独对几个编码进行讲解下:
- ISO 8859-1 正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。曾推出过 ISO 8859-1:1987 版。ISO-8859-1是单字节编码。
- GBK(国标扩展) 全名为汉字内码扩展规范,英文名Chinese Internal Code Specification。K 即是“扩展”所对应的汉语拼音(KuoZhan11)中“扩”字的声母。GBK是对GB2312的扩展,这样GBK在支持简体中文的同时也支持繁体中文。现时中华人民共和国官方强制使用GB18030标准.
- Unicode 再来说说Unicode吧,在java或者javascript中我们构造一个“中文”的unicode串的时候一般是使用”\u4E2D\u6587”来表示,占两个字节。UTF-8则是可变长字符编码,比如一般的英文字符只需要一个字节,而中文则每个字符占用三个字节。而UTF-16两个字节为一个编码单元(固定的),所以从字节的角度来看无法和ASCII实现兼容,且UTF-16存在大尾序和小尾序的两种不同的存储形式。
字符编码贯穿java代码编译运行的始终
下面是我们需要考虑的问题:
- 源文件的编码
- 编译时的指定的编码参数(Eclipse会根据你源文件的编码格式自动选用相应的编译编码参数)
- 系统的默认编码(可以通过System.getProperty(“file.encoding”)来获取)
- 控制台终端显示所设置的编码
- 运行时JVM中的String都是Unicode编码
首先我们通过一个简单的java代码的编译运行来说明编码在这个过程中的使用
package com.lukejin.stringtest;
import java.io.UnsupportedEncodingException;
public class StringTest {
public static void main(String[]args) throws UnsupportedEncodingException{
String chinese="ab中文";
System.out.println(chinese);
}
}这个代码看起来非常简单。
假设源文件的编码格式是GBK,那么当你通过相关可以查看二进制格式的软件查看的时候你可以发现如下编码
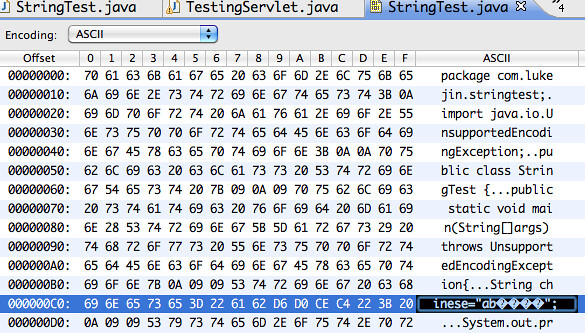
这时我们可以知道”中文”的GBK编码为 D6 D0 CE C4(GBK编码一个中文占两个字节)
在使用Eclipse编译之后(eclipse编译时帮你自动添加了编译参数 -encoding gbk),你可以通过二进制编辑器打开编译后的class
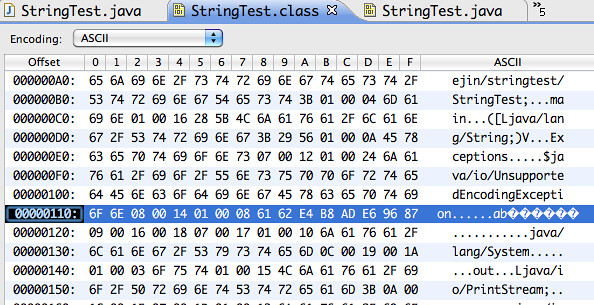
这是编译之后的”中文”已经被转换成UTF-8的编码了三个字节表示一个中文字符。 E4 B8 AD E6 96 87
那么在JVM中运行的时候是怎么一种情形呢? 首先chinese是一个正确的”ab中国”的Unicode字符串, System.out.println(chinese); 这句会将chinese按照系统默认的编码encode成字节流送到输出流里, 然后终端里会对输出的流里的字节按照终端的编码进行decode得到字符
和编码有关的两个方法
关于String的编码有两个比较重要的方法需要提及
getBytes(String charset)
new String(byte[] bytes,String charset)
这两个方法都是相对于String而言,即相对于Unicode字符串而言。
这里我们就来详细讲解下这两个函数的功能,
GetBytes是将字符串中的一个个字符char按照charset对应的编号进行编码,得到的是编码后的字节数组,这是一个encode的过程,
而new String(byte[] bytes,String charset) 是将byte数组按照charset去解码,将解出来的一个个字符用unicode字符存储,并返回这个unicode字符串。
下面以实例和图的方式展示上面的过程
假设String a=”中文”;//当然你可以以unicode的形式写成String a=”\u4E2D\u6587″;
Byte[] bs = A.getBytes(“gbk”)

String b= new String(bs,”iso-8859-1″);//如果这里使用gbk编码进行解码的话,会自然的得到原来的a
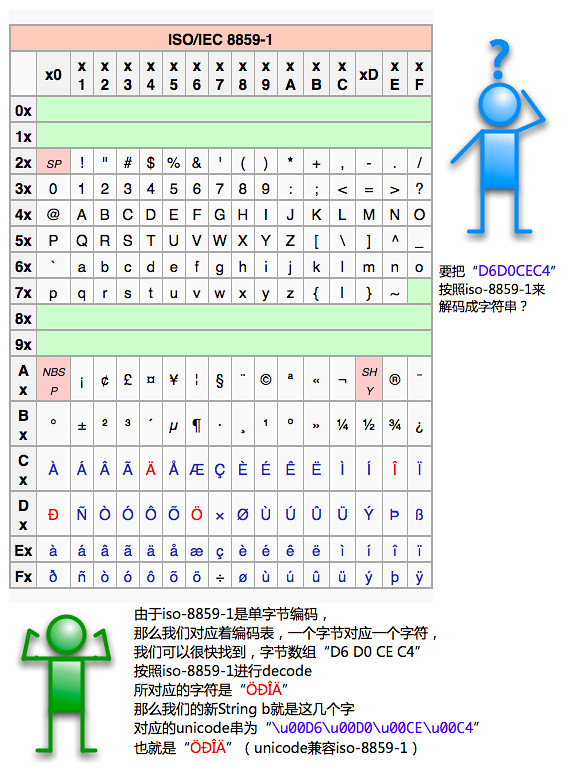
可以看出这个时候已经为乱码了,不过由于没有信息丢失,所以还是可以恢复成中文的。 恢复的过程为 String c = new String(b.getBytes(“iso-8859-1″),”gbk”); 这个过程可以参考上面的两个图进行思考。 首先b按照iso-8859-1进行编码得到”D6D0 CEC4” ”D6D0 CEC4”按照GBK进行解码得到字符串”中文” “中文” 分别使用unicode进行表示(由于java中String都是unicode),所以b为”中文”(”\u4E2D\u6587″)
Web编程中常见的编码问题
那为什么我们需要在java中进行所谓的转码呢? 关键原因就是我们构造字符串的时候使用了错误的字符集。 比如前台传过来的是gbk编码的字节流bytes,但是服务器端却错误的以iso-8859-1的字符集解码成字符。 这个过程相当于 new String(bytes,”iso-8859-1”); 当然很多时候这个过程不是由我们来写的,而是由servlet框架来完成,当然你可以改变这个字符集的值。
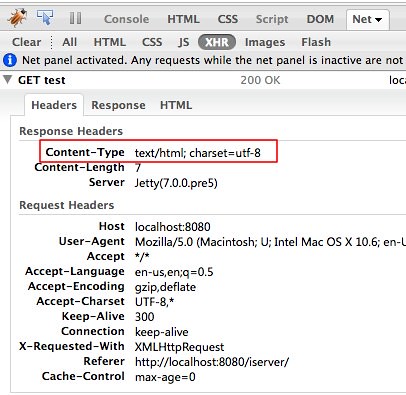
我们Servlet后台发送响应给前台,这里会有一个编码的概念,就是你输出的内容的编码,以及设置的让接受端浏览器以什么样的编码来解码。 比如我们可以在通过在response.getWriter();之前使用
response.setContentType(“text/html; charset=utf8″);
这样的语句来设置输出的编码,其实这个语句起两个作用,
第一,设置了输出内容的编码方式 比如我们有一个a这个字符串,那么将它发送到浏览器的时候肯定都是字节流,那些字节是这样的a.getBytes(你上面这个设置的编码) 第二,发送给浏览器的response的报头中的编码设置成这个编码,使得浏览器可以以正确的编码去解码字节数组。
当然Servlet 2.4版本以后,提供了setCharacterEncoding这个一个单独的方法可以单独设置编码的。这个你可以通过阅读相关web容器的源码得知。
这两个方法都必须在 response.getWriter();之前作用才起作用,且响应的字节流编码字符集和response的header的contentType的charset是一致的。
这里举一个我碰到的问题: 后台有一个Servlet是前台的一个JQuery的ajax调用的,返回一个包含中文的字符串,由于历史原因,得到字符串是以iso-8859-1解码的得到String a.且系统的默认编码是iso-8859-1编码的,如果我们将这个a直接在控制台上print出来,却发现能够正确的输出中文,(心想:奇怪了,不应该出现中文?)其实原理是这样的,输出到控制台经过如下两个步骤, 首先1.将错误的String按照iso-8859-1进行编码成bytes,这个bytes和正确的gbk编码的bytes是一致的,这个时候我们的SecureCRT设置的编码是GBK,所以能够正确的显示中文,也就是我们以GBK的方式去解码一个iso8859-1的编码,歪打正着,中文反而能显示了。
现在回到Web上来思考,由于response写出的字节编码和浏览器解析的编码是一致的(如果不一致,我们可以模拟控制台的方式) 所以我们必须先做一个转换 String b = new String(a.getBytes(“iso-8859-1″),”gbk”) 这样,b中的字符串就是正确的字符串, 这个时候我们只要以支持中文的编码送到客户端的浏览器就可以了
response.setContentType(“text/html;charset=utf-8″); out = response.getWriter(); out.write(str);
很多时候,一些同学烦扰乱码还和javascript相关,这个主要的原因是,其实在js的运行时的内部,String也是以Unicode进行编码的,(或者准确的说时utf-16)。 所以在进行ajax的使用的过程中,同学们容易遇到一些乱码问题的困扰。需要注意的是服务器端返回给ajax的字节只要保证是正确的编码就可以了。(比如中文的话,只要保证是相应中文的正确的gbk,utf-8等编码)
乱码的总结
在Java运行时的世界里,乱码产生(编译时产生的这里不管)的源头存在于两个地方,其实也就是我上面提及的两个函数(当然有时候是框架帮我们调用了其中的某个函数,所以你得到的已经是一个由网络上传过来的字节数组转换后的String了),
getBytes(String charset) 如果按照指定的charset去对一个unicode String进行编码,但是发现这个编码体系里(比如iso-8859-1)没有这个字符,那么就会编码成3F(其实就是一个问号),这样就造成了信息的丢失了,是不可以恢复的。 new String(byte[] bytes,String charset) 如果对一个字节数组按照指定的字符集去解码,但是字符集突然对其中一段编码不认识的时候,例如某一段字节数组按照UTF-8解码的时候,不认识了,到了unicode字符串这边就是”\uFFFD”,其实这个东西叫做’REPLACEMENT CHARACTER’,显示的是一个问号
具体可以查看 Unicode Character ‘REPLACEMENT CHARACTER’ (U+FFFD) 所以这个地方也肯定发生了信息的丢失,无法恢复的。如果大家想不明白的可以直接按照上面的图类似的想法。 所以我们碰到的乱码往往是下面的情况
- 一种编码的文件以另一种编码的方式去解析读取,这样肯定出现乱码,这在我们的操作系统里打开文件的时候经常出现。
- 以错误的编码方式对传过来的字节流进行了解码。所以得到了错误的unicode字符串。
- 以和控制台不一致的编码对正确的unicode字符串进行编码,并送至控制台显示。会出现乱码。